Trained on a mixture of 320x512, 384x512, 512x512, 512x384 and 320x512 images, with the major majority being body shots, 89 of the images had a visible face.
With a backlog of now ~13 V2 dreambooth attempts I merged some of those models together coupled with the abdl checkpoint here on civitai and AiFogs PaciModel putting a larger emphasis on the text encoder and overall image data of my dreambooth models, but lending some of the quality improvements for things like anatomy without ruining the models understanding of diaper.



























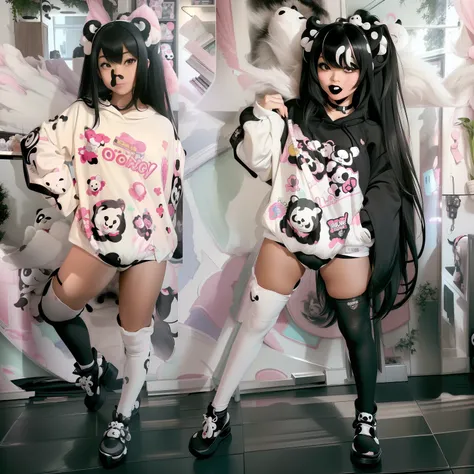
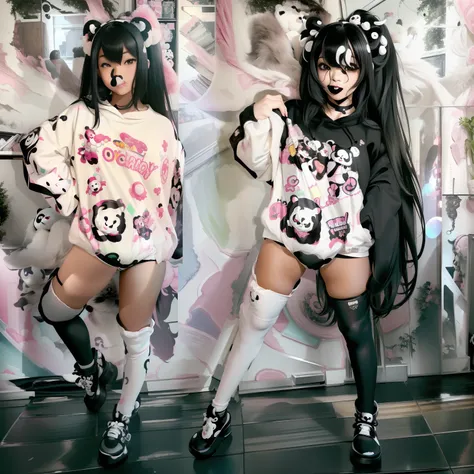

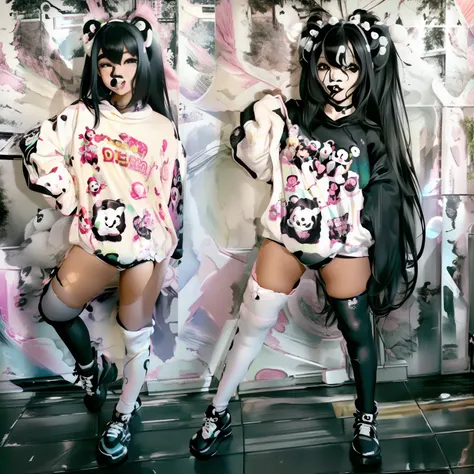



Trained on a mixture of 320x512, 384x512, 512x512, 512x384 and 320x512 images, with the major majority being body shots, 89 of the images had a visible face.
With a backlog of now ~13 V2 dreambooth attempts I merged some of those models together coupled with the abdl checkpoint here on civitai and AiFogs PaciModel putting a larger emphasis on the text encoder and overall image data of my dreambooth models, but lending some of the quality improvements for things like anatomy without ruining the models understanding of diaper.